
Talvolta può risultare utile e/o dilettevole vedere foto antiche o leggere articoli di molti anni fa che danno un’immediata sensazione di come i tempi siano cambiati nel tempo: al di là dei contenuti degli articoli, è la stessa forma con cui sono scritti che spesso stupisce!
Diversi sono i gruppi Facebook (talvolta gruppi chiusi che quindi richiedono l’autorizzazione per entrare a farne parte) dove vengono pubblicate immagini di Torino “com’era” (e.g. TORINO ieri e oggi; TORINO PIEMONTE Grup Antiche Immagini; Archivio Storico della Città di Torino; Torino sparita; Turin d’antan; Giorgio Pelassa). Sempre su Facebook ci sono poi siti, non necessariamente istituzionali, che forniscono informazioni su luoghi specifici con molte fotografie, come ad esempio STUPINIGI con le sua bellissima sezione di foto: ad esempio, qui ho trovato foto del trasporto della copia dell’elefante Friz nella Reggia di Stupinigi oltre a quelle degli edifici utilizzati un tempo per custodire gli animali esotici dei Savoia (Managerie Fagianerie e Serragli a Vicomanino).
Di interesse sono anche alcuni forum quali quello di Torino sparita, presente nel sito skyscrapercity.com, dove di possono trovare antiche cartoline ed immagini inserite anche da privati e per questo difficilmente reperibili altrove. In quel medesimo sito esiste poi anche un forum su Torino, utile se si cercano informazioni sulla città e foto più recenti. Ovviamente trovare una foto si uno specifico posto in un forum non è particolarmente agevole, ma a tale scopo può comunque venire incontro la possibilità di effettuare una ricerca su del testo digitato che accompagna ciascun post:
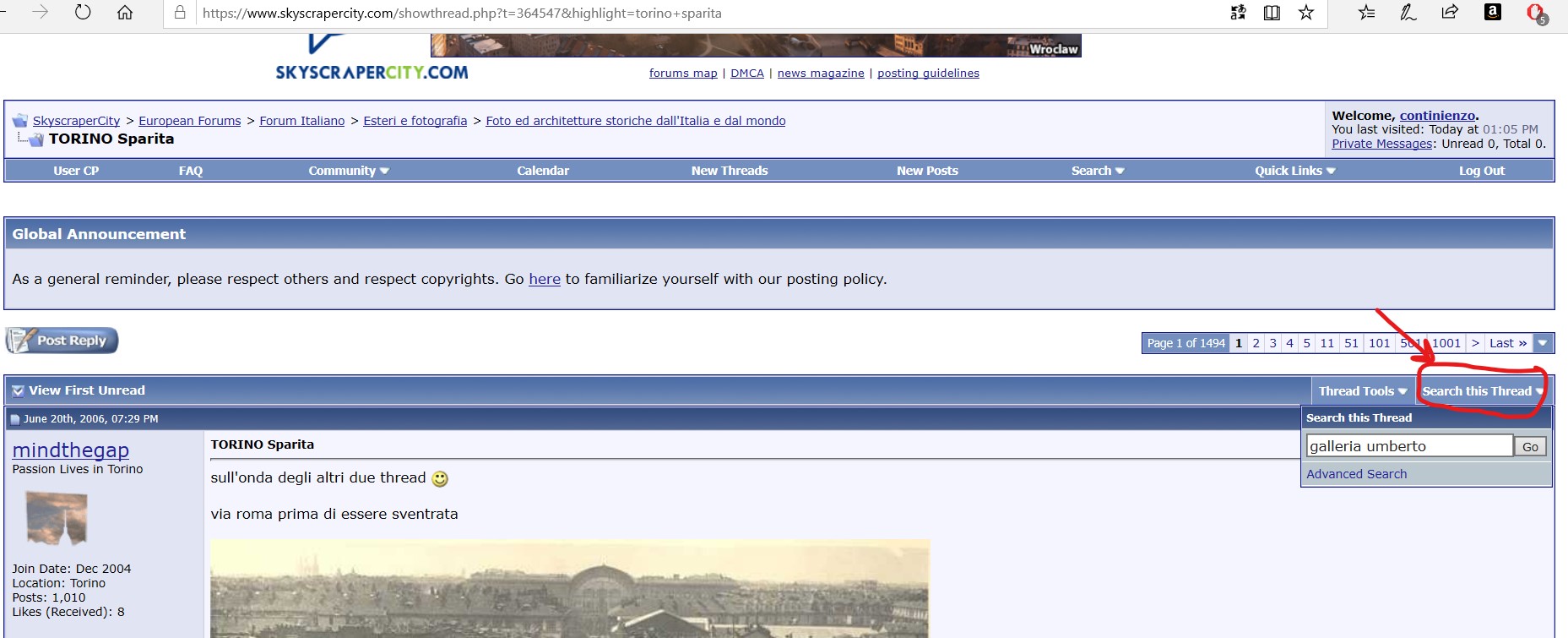
Funzionalità di Search presente generalmente nei forum ed anche in quello di Torino sparita in Skyscrapercity.com
Esistono poi anche ulteriori fonti consultabili, anche se forse meno agevolmente.
Interessantissimo è il sito atlanteditorino dove esiste anche una sezione di fotografie anche storiche: ad esempio si possono reperire diverse immagini della incredibile Galleria Nazionale (di cui non conoscevo neppure l’esistenza), andata persa in quella orribile opera di distruzione operata per far spazio a via Roma. Viene da domandarsi come certe opere di distruzione si siano potute operare ancora solo un secolo fa!! Seppure siano di foto a bassa risoluzione risultano davvero uniche!

Album presente nel sito atlanteditorino, relativo alla distrutta Galleria Nazionale di Torino
Purtroppo non mi sembra esistere nel sito una funzione specifica per ricercare l’immagine di un particolare luogo di interesse per cui penso l’unica strada è quella di utilizzare le funzionalità di ricerca generali presenti in ogni browser, una volta che si è andati sulla sua pagina specifica delle fotografie. Aiuta comunque andare sulla seguente mappa che mostra i posti in cui ci sono foto relative all’inizio ‘900 e quest’altra per le foto precedenti della seconda metà dell’800.

Mappa che mostra i posti in cui ci sono foto relative alla seconda metà dell’800
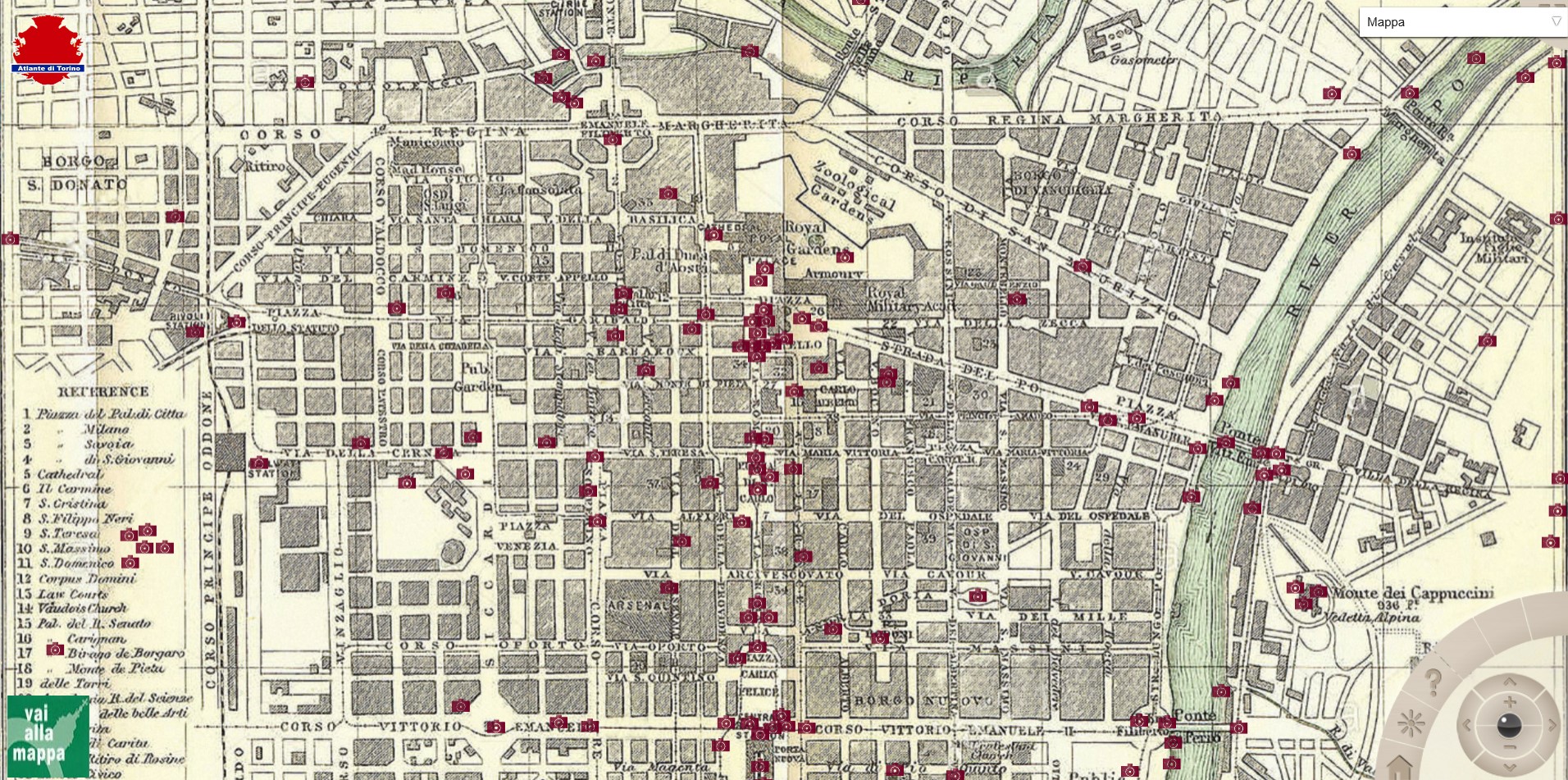
Mappa che mostra i posti in cui ci sono foto relative all’inizio ‘900
Ad esempio, la Fondazione Torino Musei fornisce l’accesso all’archivio fotografico Gabinio: le immagini non ad alta definizione vengono rilasciate gratuitamente come OpenData in diversi formati (XML, CSV, XLS, XLSX, JSON). Oltre all’archivio del Fondo Gabinio, sono disponibili, su quel medesimo sito, anche dataset su Palazzo Madama, GAM e MAO. Si legge che sono presenti i “dataset relativi agli elenchi e alle schede anagrafiche di tutte le opere corredate di fotografia presenti nei cataloghi informatizzati dei musei” e che questi “dati sono aggiornati annualmente” niente male!

Scaricando, ad esempio il file contenente gli OpenData in formato json, generalmente quello più utilizzato quando il contenuto deve essere inviato e processato da una applicazione client, si ottiene un file con i seguenti dati strutturati su cui si possono agevolmente effettuare, tramite la funzionalità di Cerca dell’editor, delle ricerche su termini specifici (e.g. ricerca sul termine Michelotti), in modo da individuare le immagine di interesse: in particolare, associata a ciascuna immagine è indicata l’URL da utilizzare per scaricarla (e.g. http://93.62.170.226/foto/gabinio/001B1.jpg), oltre ad altre informazioni interessanti quale ed esempio la sua presunta datazione.
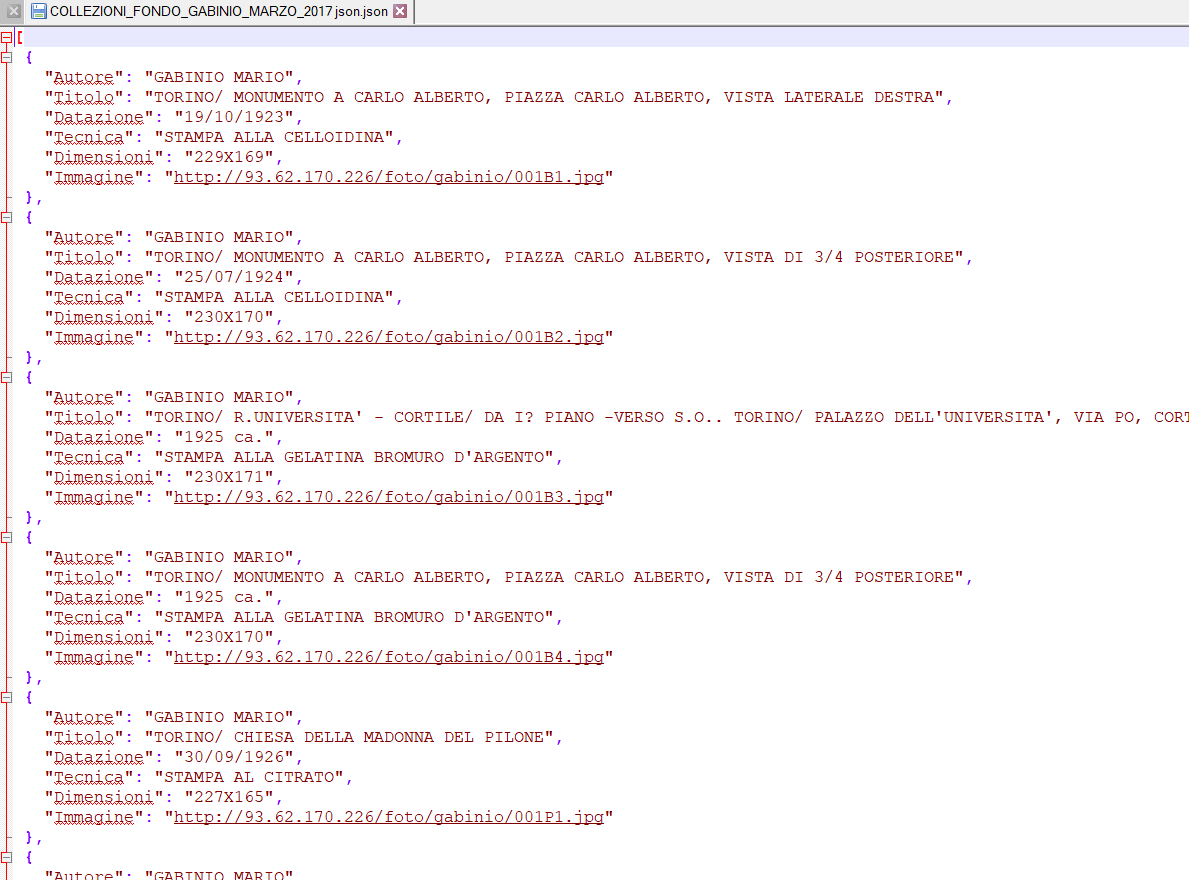
Contenuto del file http://www.fondazionetorinomusei.it/sites/default/files/COLLEZIONI_FONDO_GABINIO_MARZO_2017%20json.json
Anche MuseoTorino fornice delle API che consentono a tutti gli utenti, enti o organizzazioni pubbliche e private, di usare i dati presenti sul loro sito: la procedura per sapere come sono fatte e come quindi poterle utilizzare non è esplicitato nel sito, ma è sufficiente contattarli via email, come indicato, per scoprire la collocazione del file pdf contenente le informazioni necessarie. Si tratta anche in questo caso di Opendata, quindi utilizzabili senza particolari restrizioni. Personalmente ne sto valutando l’utilizzo, magari anche solo utilizzando un client generico come l’add-on RESTclient di Firefox, Postman di Chrome o il Microsoft.Rest.ClientRuntime. Si può comunque accedere ai contenuti anche semplicemente utilizzando la sezione Il museo dove si può filtrare la ricerca in base alla cronologia, al tema ed alle categorie.
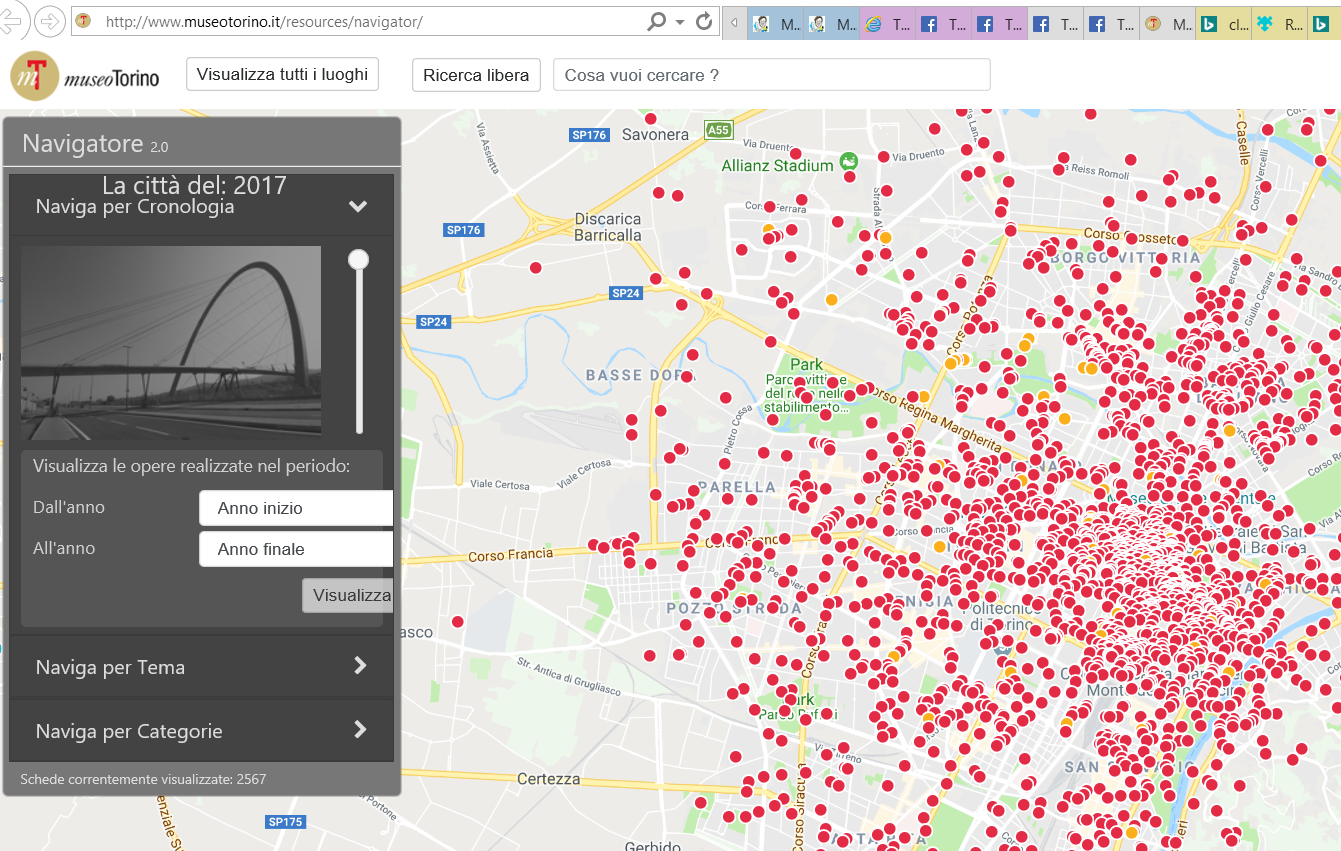
Sezione Il museo del sito MuseoTorino dove si può filtrare la ricerca in base alla cronologia, al tema ed alle categorie.
Interessante è poi la rivista Torino Storia che ha sia un sito sia un account Facebook dove si possono reperire informazioni utili anche senza dover necessariamente acquistare la rivista che può fornire ovviamente maggiori dettagli, per cui può valer la pena averla o consultarla in qualche biblioteca civica.

Il sito Censimento Fotografia propone poi ulteriori immagini molto interessanti e da cui si raggiunge il link dell’Archivio Storico della Città di Torino dove è presente la collezione Chiambretta.

http://www.comune.torino.it/archiviostorico/ – http://www.censimento.fotografia.italia.it/enti/archivio-storico-della-citta-di-torino/
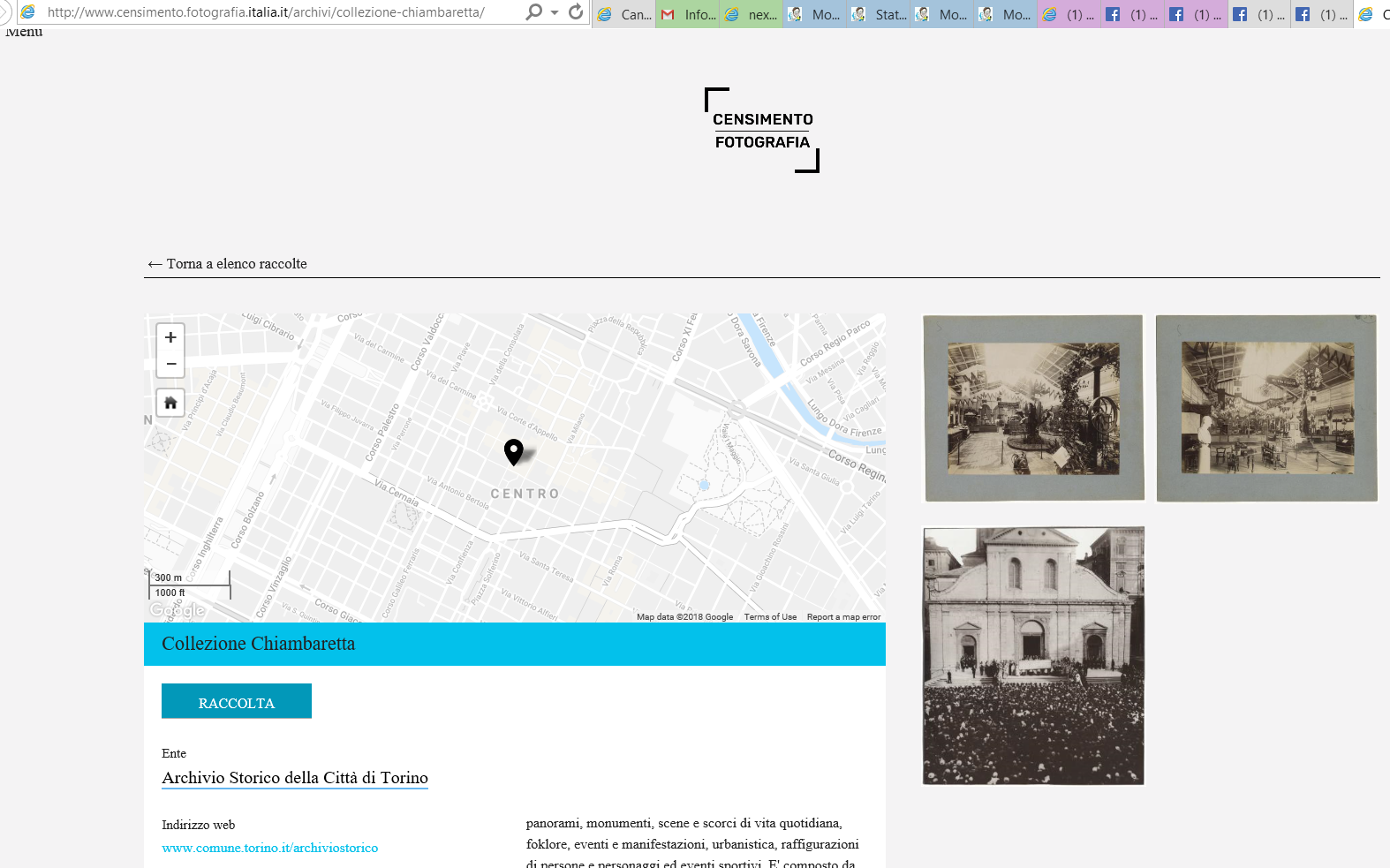
Anche i motori di ricerca possono agevolmente venirci in aiuto nel ricercare immagini ed archivi. Ad esempio ricercando archivio storico chiambretta si trovano diverse immagini di quell’archivio e, ad esempio dall’articolo Torino, un museo del cinema fatto in casa, si apprende come si tratti di una raccolta privata di un appassionato, donata alla città di Torino.
Certo di non essere stato esaustivo e ben conscio che molte ancora sarebbero le fonti da citare, indico solo ulteriori link interessanti:
- archivio-foto-vecchie , sito spartano ma interessante, con foto storiche di Passatore
 L’iniziativa dell‘Archivio Nazionale Cinema d’Impresa di Ivrea che lancia «Mi ricordo», la microstoria del Piemonte narrata dai Super 8.
L’iniziativa dell‘Archivio Nazionale Cinema d’Impresa di Ivrea che lancia «Mi ricordo», la microstoria del Piemonte narrata dai Super 8.

Mi ricordo– microstoria del Piemonte narrata dai Super 8.
Non si può poi non indicare come enorme fonte di informazione il bellissimo archivio storico de La Stampa dove è presente la digitalizzazione delle testate del giornale dalle sue origini (1867) fino al gennaio 2006: peccato che non abbiano proseguito poi nei successivi anni, dove sicuramente sarebbe anche stato più agevole l’archiviazione, essendo il giornale sicuramente già in forma digitale.
Da quell’archivio si possono agevolmente scaricare sia le pagine in pdf di ciascun quotidiano, sia effettuare il riconoscimento dei caratteri ed averne il testo in formato .txt: ovviamente se un articolo è composto da più colonne, si devono ricercare le diverse parti e ricomporre opportunamente il contenuto (che può essere infatti intervallato dal testo di altri articoli): insomma un lavoro non immediato ma possibile!
Dalla pagina di presentazione di quel progetto si legge:
“Quasi 150 anni di storia, 1.761.000 pagine, oltre 5 milioni di articoli di giornale e 4,5 milioni di immagini tra fotografie e negativi. Questi sono solo alcuni dei numeri che danno la dimensione dell’Archivio Storico de La Stampa. Si tratta di un progetto di grande portata culturale il cui scopo è quello di creare una Biblioteca Digitale dell’Informazione Giornalistica accessibile liberamente al pubblico italiano e internazionale. […] Oggetto della digitalizzazione sono tutte le edizioni quotidiane delle testate che si sono succedute nel tempo, dalla Gazzetta Piemontese, il primo nome con cui esordì il quotidiano nel 9 febbraio 1867, a La Nuova Stampa e Stampa Sera, fino ad arrivare alla sua denominazione attuale, La Stampa. Le pagine di giornale sono state acquisite dalla copia su microfilm. Dall’immagine di ogni pagina, utilizzando software di riconoscimento testuale tra i più avanzati, è stato digitalizzato il testo e sono stati individuati gli articoli codificati in XML per consentirne la lettura, il trasferimento e la copia. […] E’ possibile accedere via web, all’URL http://www.archiviolastampa.it, all’intero archivio in modo rapido e flessibile e effettuare ricerche per data o per parole contenute nel testo degli articoli. Inoltre si può visualizzare la riproduzione delle pagine del giornale per leggerle e sfogliarle come dal vero, navigando attraverso l’intera raccolta in modo da poter accedere a qualsiasi informazione si cerchi. […] Il progetto rientra nel programma della Biblioteca Digitale Piemontese in coordinamento con la Biblioteca Digitale Italiana, che è impegnata a salvare gli archivi storici di pubblicazioni presenti sul territorio, consentendo al Piemonte di dotarsi di una Biblioteca digitale dell’informazione giornalistica“.
Nel seguito alcune informazioni che possono risultare utili per eseguire delle ricerche in quell’archivio.
Nel form di filtraggio della ricerca, sembra debba essere inserita una data precisa nel formato gg/mm/aaaa sia per la data di inizio sia per la data di fine: inserendo solo l’anno, non restituisce errore ma non sono presenti risultati. Inoltre è necessario avere un po’ di pazienza in quanto quel sito non è dei più veloci per cui è talvolta necessario attendere (anche qualche minuto) per ottenere l’informazione desiderata: in particolare, quando si richiede di scaricare il file di una pagina specifica, compare subito il popup di verifica che non si è un bot … ma l’immagine del codice da leggere si può caricare dopo molto più tempo, per cui uno rimane un po’ spiazzato se non lo sa!!
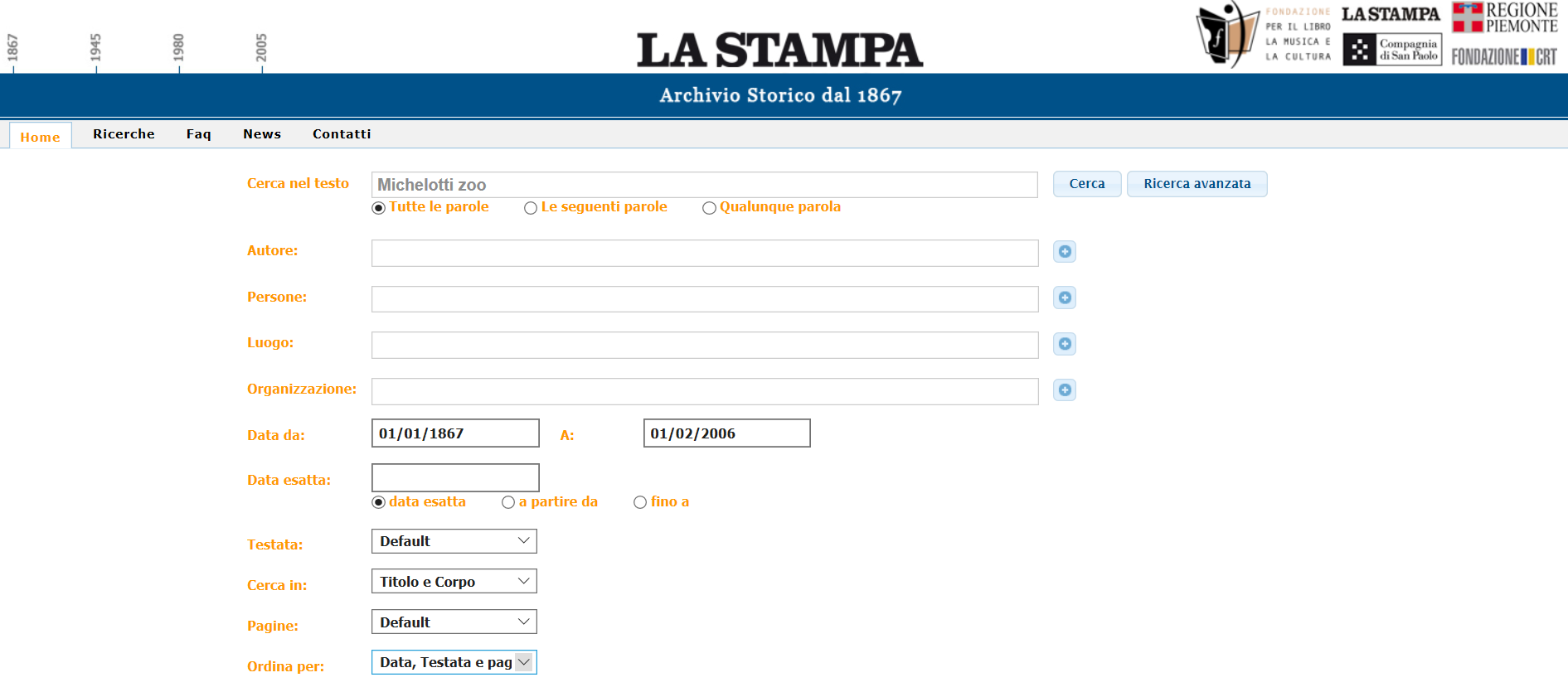
Ricerca nell’archivio storico del quotidiano La Stampa (dal 1867 al 2006)
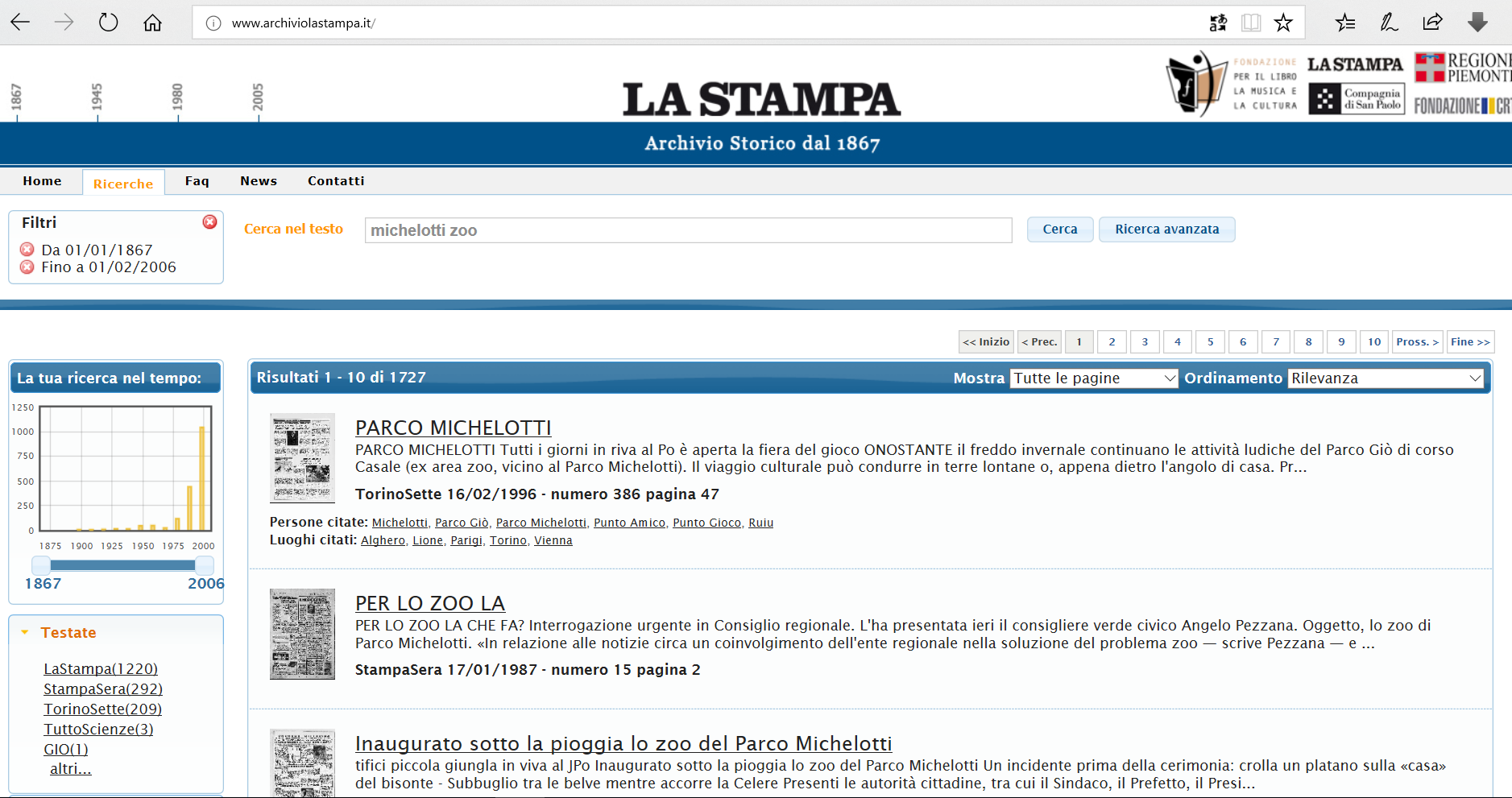
Risultati ottenuti ricercando i termini Michelotti e zoo
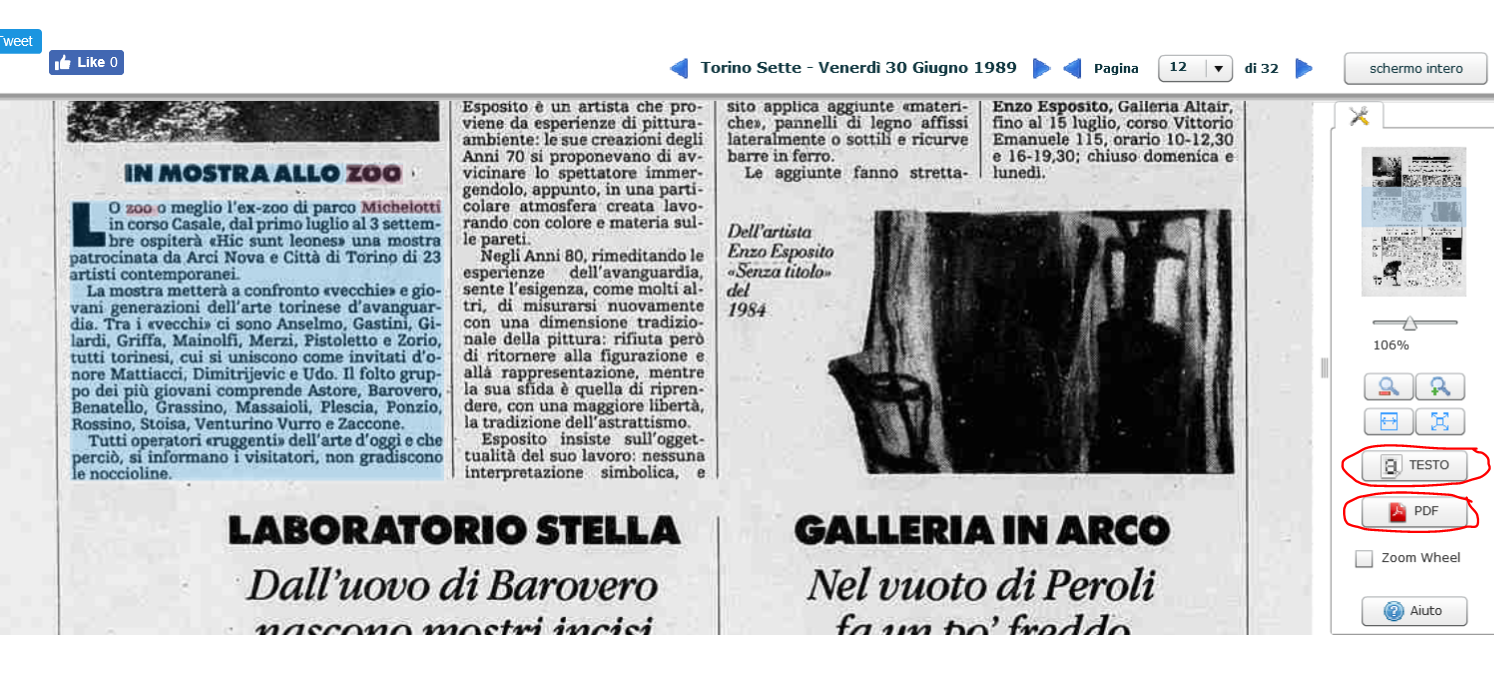
Per ottenere il pdf della pagina o il testo in .txt, premere i rispettivi pulsanti presenti nel pannello a destra
Se si scarica il pdf, questo contiene l’immagine della pagina trovata che si può ingrandire a piacere per poterla leggere direttamente. Se invece si seleziona il download del testo, viene scaricato un file .txt derivato dall’OCR di quella immagine, … senza “a capo” e formattazione, con in più ovvi errori di riconoscimento del testo. Se si desidera quindi ricercare il testo di un articolo particolare, è quindi necessario utilizzare la funzionalità Cerca dell’editor utilizzato e copiare le parti di testo che possono essere anche non continuative qualora l’articolo sia in più colonne … e dopo rileggere il tutto per correggere le parti di testo non riconosciute correttamente, magari utilizzando l’immagine originale scaricata in pdf.
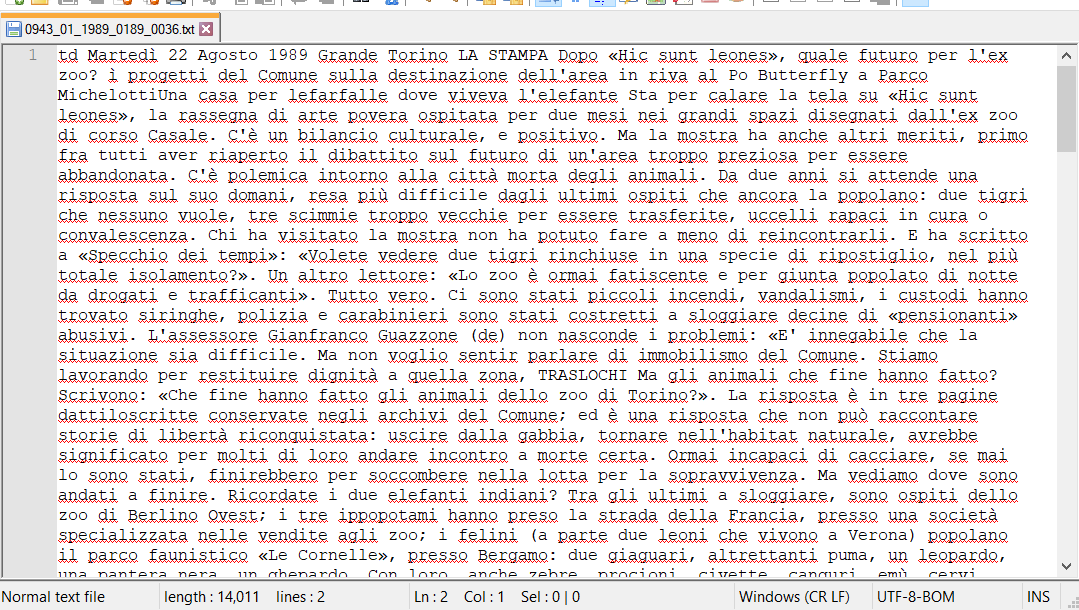
File .txt con il testo derivato dall’OCR del testo presente nell’immagine della pagina di quotidiano
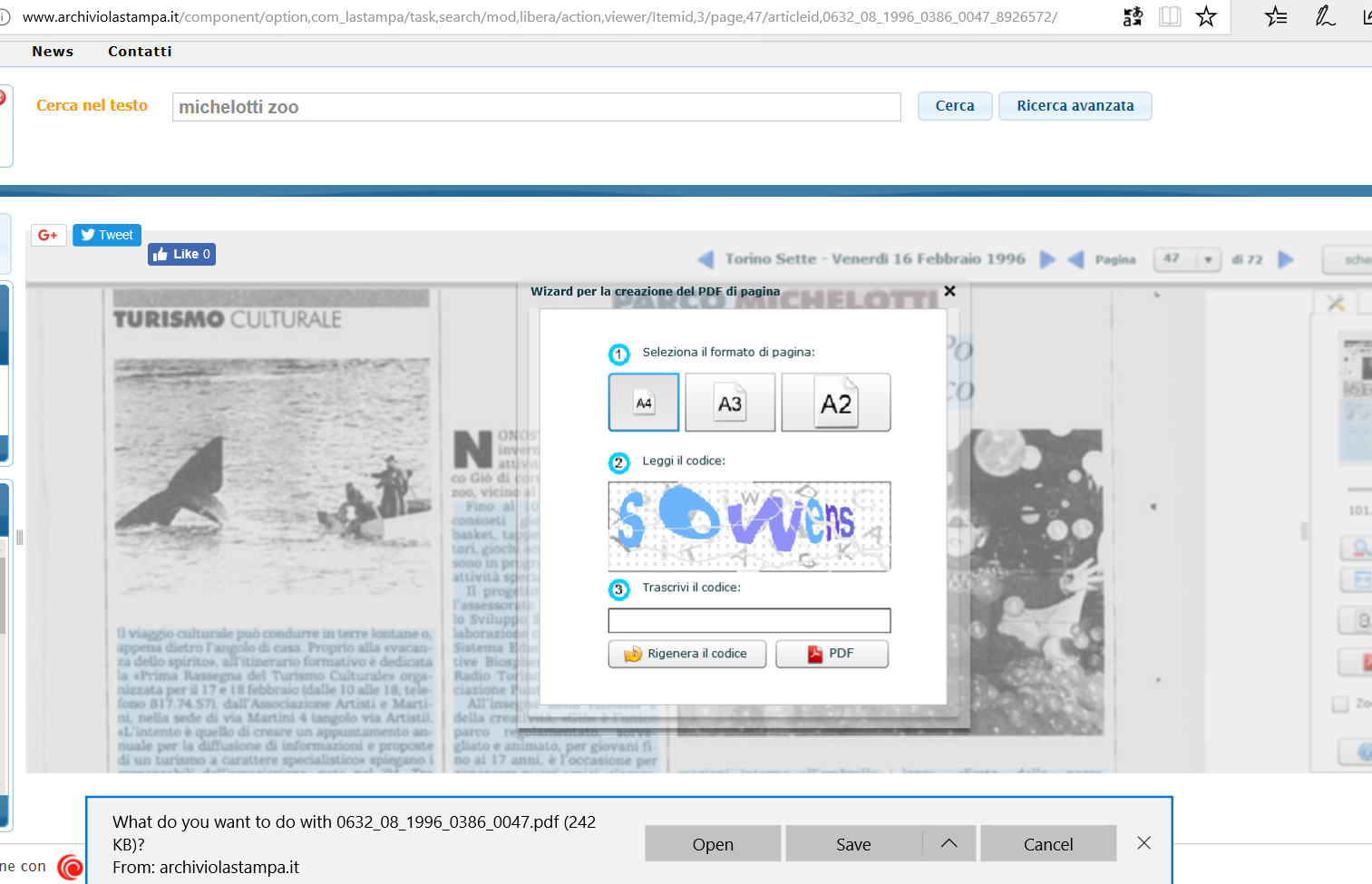
Dopo aver inserito il capta per verificare che non sei un robot, viene scaricato il file richiesto (NOTA: può essere necessario attendere molto per vedere caricata l’immagine con il codice da trascrivere)
Internet Archive: ricercando qui, ad esempio, “Michelotti” si trovano digitalizzati due testi ( Sperimenti idraulici I del 1767 e Sperimenti idraulici II del 1775) del prof. Francesco Domenico Michelotti della Regia Università di Torino, padre di Ignazio Michelotti

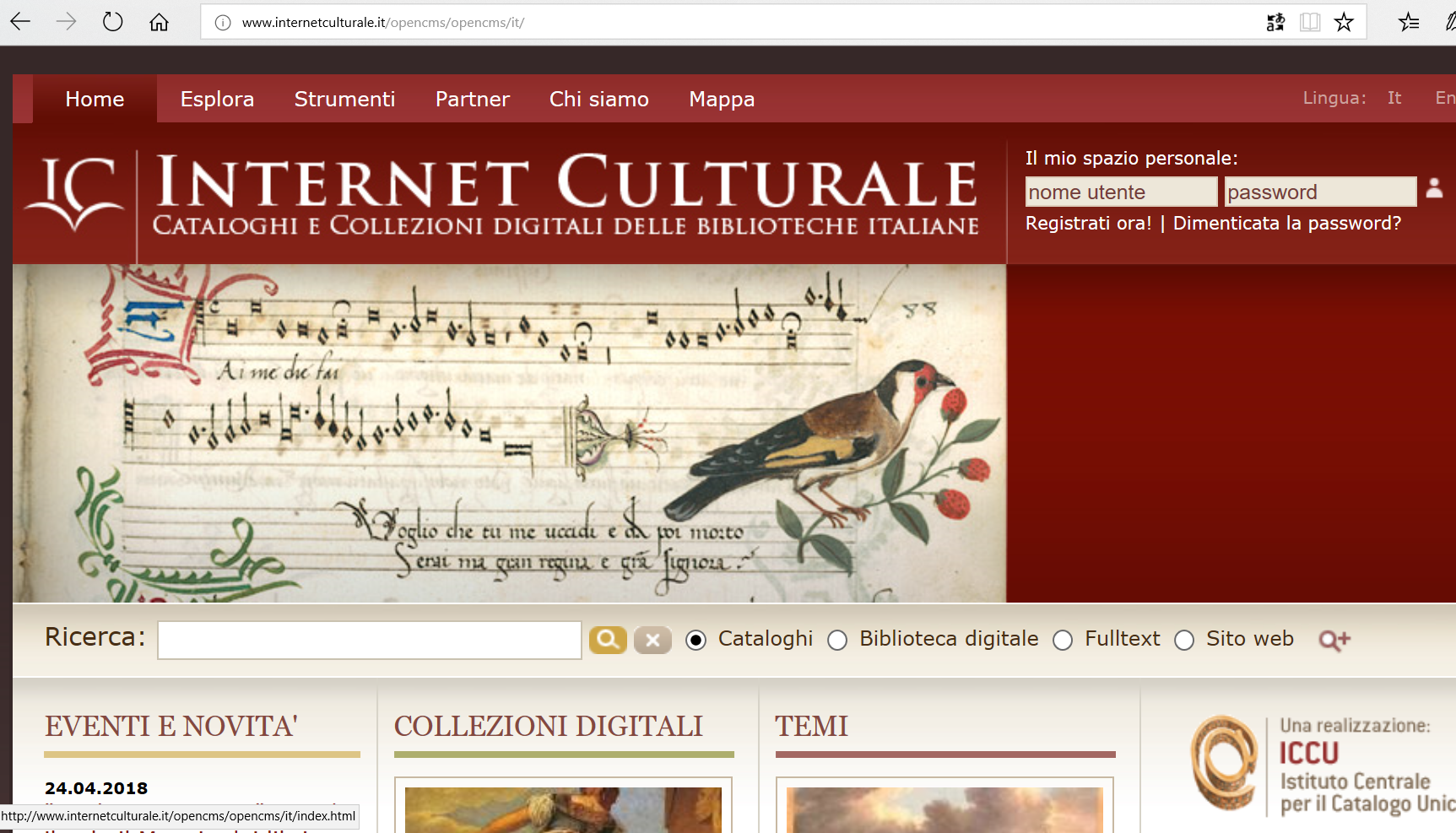
Da non dimenticare sono poi le biblioteche civiche con il loro Biblioteche civiche torinesi – catalogo in linea.


___________________
Anche i motori di ricerca possono ovviamente essere utilizzati per reperire foto, anche se difficilmente si trovano subito i risultati voluti … ma talvolta le immagini presentate sono davvero interessati e provenienti da chissà quale sito diversamente trovabile! … e vale la pena effettuare una ricerca con più motori di ricerca almeno i principali cioè Google e Bing, perché i risultati ottenuti saranno sicuramente differenti.
Ricerca di immagini con Google
Ricerca di immagini con Bing
=============================================================
Se si desidera poi cercare di abbellire una foto antica, riportandola , ovviamente è possibile effettuarlo con un buon programma di fotoritocco (e.g. Photoshop, Affinity Photo) ma anche utilizzando tool online.
Segnalo il sito https://colourise.sg che consente gratuitamente di provare a “colorare” automaticamente una foto originariamente in bianco e nero … con risultati talvolta incredibili!
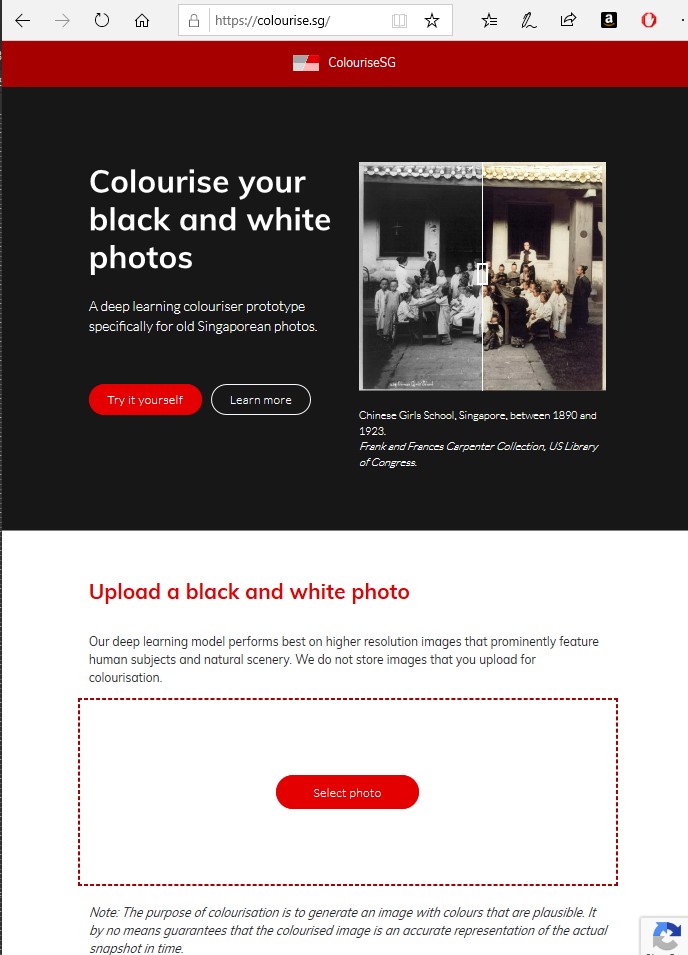
=============================================================
Se si vuole poi essere avvertiti ogni qual volta viene pubblicata qualche informazione sul web relativa ad un certo argomento (o che faccia riferimento alla propria email o nominativo), è possibile utilizzare il servizio Alerts di Google. Questo interessante servizio gratuito consente appunto di indicare una o più stringhe ed essere avvertiti, via email, quando il motore di ricerca rileva qualche nuovo riferimento su web ad essi relativi.

Registrazione/gestione di una parola (o stringa) su cui ricevere un alert via email quando viene pubblicata su web
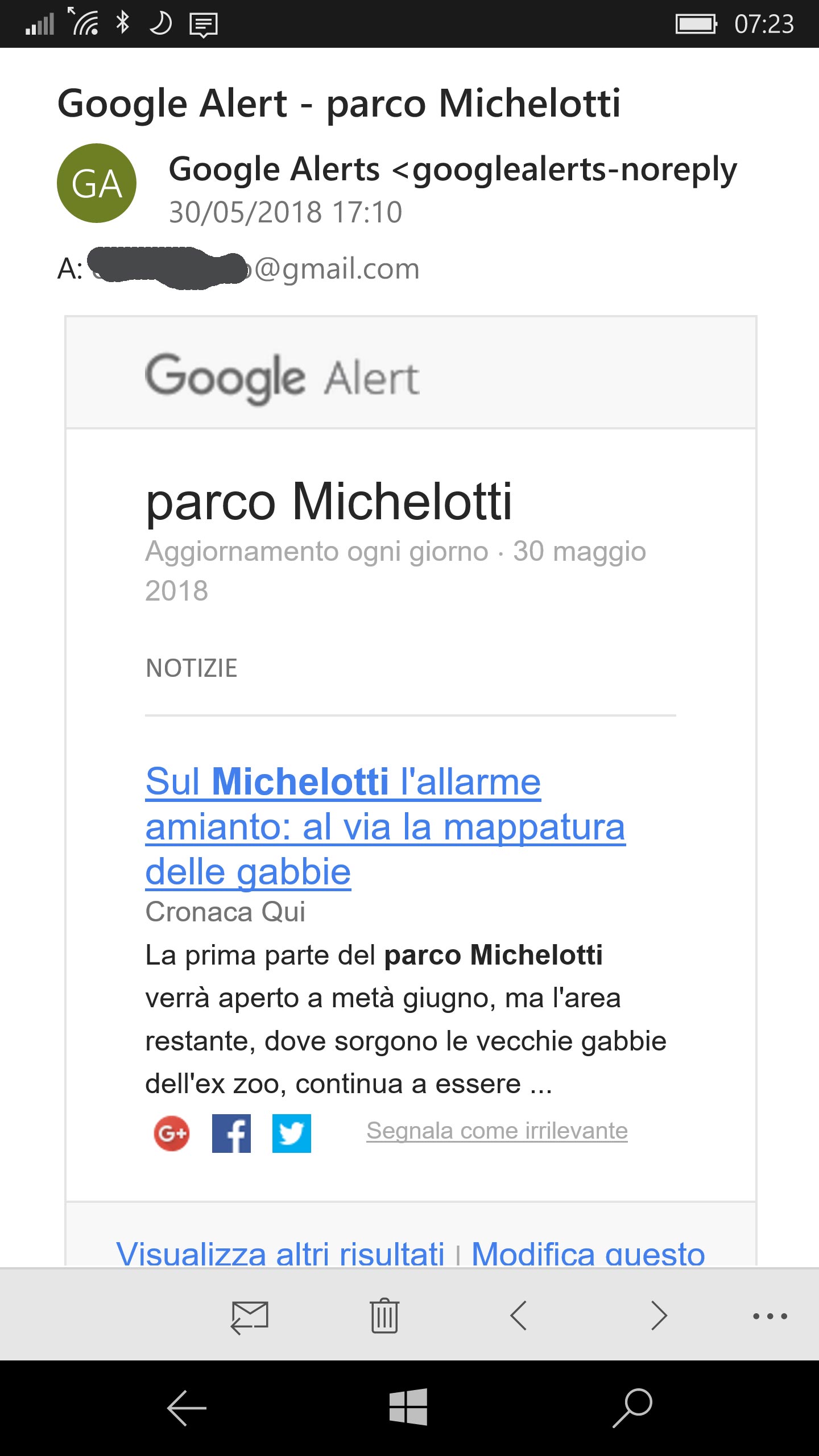
Email con il link contenente il nuovo articolo pubblicato su web e contenente la parola/frase desiderata
=============================================================
Ci sarebbe ancora molto da dire … ma per intanto pubblico questo post, rimasto privato in quanto incompleto forse per troppo tempo, riservandomi di integrarlo a breve!
Ovviamente se avete suggerimenti di altri archivi storici fotografici di interesse fatemeli sapere commentando il post!
;-)============================================================






{kind=link}
Pingback: Non tutto il male vien per nuocere: visite gratuite (virtuali), musica, film ed offerte di ogni genere ai tempi del coronavirus | Enzo Contini Blog
Pingback: Il parco Michelotti e le vicende del giardino zoologico desunte dagli articoli dei quotidiani | Enzo Contini Blog